本文介绍在MySQL中查询每个分组最新一条数据的正确方法。直接使用GROUP BY和ORDER BY可能无效,因为GROUP BY先执行。解决方案包括:在子查询中使用ORDER BY id DESC LIMIT确保排序,或使用MAX(id)子查询连接原表。关键点是子查询中ORDER BY需要LIMIT来防止优化忽略。
### mysql 分组查询最新一条数据
**简介** mysql 分组查询最新一条数据
[](https://www.choudalao.com/article/295)需求
===========================================
下面是一张日志表
```java
CREATE TABLE `user_audit_log` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT 'user表主键',
`status` tinyint(2) NOT NULL COMMENT '审核状态1: 通过 2:不通过',
`reason` varchar(2048) NOT NULL DEFAULT '' COMMENT '审核不通过原因',
`auditor_id` int(10) unsigned NOT NULL COMMENT 'sys_users表主键',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_uid` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=235 DEFAULT CHARSET=utf8mb4 COMMENT='用户入驻审核记录表';
```
现在要查询每个用户状态为3的,最新一条数据;
可能我们第一时间想到的就是,先对`id`进行倒叙,然后`group`一下 `user_id`,`sql`如下:
```java
SELECT `id`, `user_id`, `status`, `reason` FROM `user_audit_log` WHERE `status` = 3 GROUP BY `user_id` ORDER BY `id` DESC
```

但是,当把分组去掉的时候,你会发现,其实得到的不是最新一条的记录
```java
SELECT `id`, `user_id`, `status`, `reason` FROM `user_audit_log` WHERE `status` = 3 ORDER BY `id` DESC
```

截图中`user_id`\=53的数据,`reason`字段最新记录的值是`会一样吗`,但分组后的却不是,说明这样是有问题的。
这是因为mysql先分组再排序,这边排序是对已经分组过滤掉的数据进行排序的,而默认分组取的是每个分组的第一条,所以,结果不是我们想要的。
因为 `user_id`\=53 的数据会比较多,我们在上面的基础上,再加一个条件 `user_id`\=53 来验证结果。下面是`user_id`\=53的倒叙数据。

既然分组后排序不起作用,那我们先进行倒叙,再把数据进行分组,这样取得第一条就是我们想要的,
```java
SELECT
*
FROM
( SELECT `id`, `user_id`, `status`, `reason` FROM `user_audit_log` WHERE `status` = 3 AND `user_id` = 53 ORDER BY `id` DESC ) AS t
GROUP BY
t.user_id
ORDER BY
user_id DESC,
id DESC
```
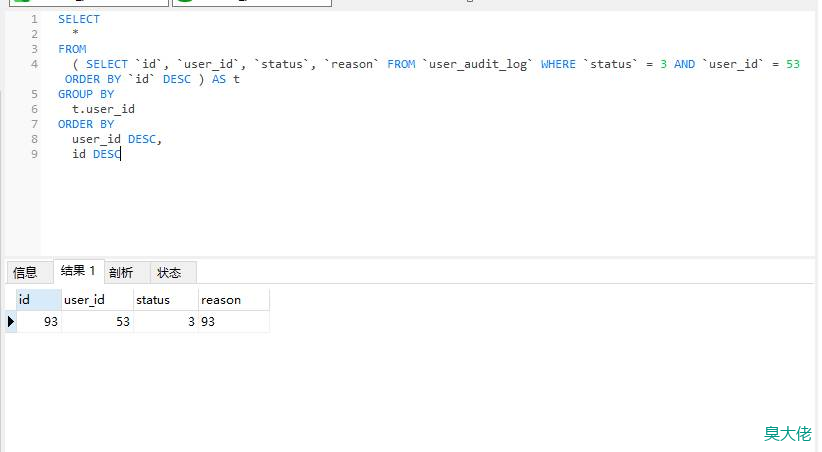!
从结果上看,并不是我们想要的,
我们调整`order`字段,效果也是一样的
```java
SELECT
*
FROM
( SELECT `id`, `user_id`, `status`, `reason` FROM `user_audit_log` WHERE `status` = 3 AND `user_id` = 53 ORDER BY `id` DESC ) AS t
GROUP BY
t.user_id
ORDER BY
id DESC,
user_id DESC
```
这是因为当子查询的`order by`语句后面没有`limit`关键字时,数据库会自动优化,即忽略`order by`语句。因此只需要添加`limit`关键字即可。
```java
FROM
( SELECT `id`, `user_id`, `status`, `reason` FROM `user_audit_log` WHERE `status` = 3 ORDER BY `id` DESC LIMIT 1000 ) AS t
GROUP BY
t.user_id
ORDER BY
user_id DESC,
id DESC
```

**`OR`**
>mysql取分组数据中每个分组的最新一条数据
>select * from data td,(select max(id) id from log group by name) md where td.id = md.id
这次就是我们想要的结果了。
[](https://www.choudalao.com/article/295)总结
===========================================
**`group by`先于`order by`执行;
当子查询的`order by`语句后面没有`limit`关键字时,数据库会自动优化,即忽略`order by`语句;**
本文转自 [https://www.choudalao.com/article/295](https://www.choudalao.com/article/295),如有侵权,请联系删除。






评论